
Como funciona a modelagem multidimensional
Hoje vou continuar o resumo do material disponível no curso de ciência de dados, na disciplina de Modelagem de Banco de Dados.
Quando falamos de apoio à tomada de decisão (BI, relatórios gerenciais, dashboards, análise de vendas, churn, etc.), o tipo de pergunta muda bastante em relação aos sistemas transacionais do dia a dia.
Em vez de “registrar uma venda”, a pergunta passa a ser:
- Quanto vendemos?
- Quando vendemos?
- O que foi vendido?
- Onde foi vendido?
- Para quem foi vendido?
Ou seja, analisamos Fatos relevantes sob diferentes Dimensões. O modelo dimensional é justamente o mais adequado para esse tipo de análise.
Um Fato é um evento de negócio que desejamos analisar, normalmente associado a medidas numéricas (quantidade, valor, custo, lucro, etc.).
Exemplo clássico para entendermos do que estamos falando:
Fato a ser analisado: Compra (ou Venda)
As perguntas típicas quebram esse fato em dimensões:
Quem? → Dimensão Cliente/Comprador
Níveis: pessoa, faixa etária (“jovem”), classe socioeconômica (“classe B”), segmento etc.
Quando? → Dimensão Tempo
Níveis: ano, semestre, trimestre, mês, dia.
O que? → Dimensão Produto
Níveis: categoria (“camisa”, “sapato”, “eletrodoméstico”), marca, linha.
Onde? → Dimensão Geográfica
Níveis: região, estado, cidade, bairro, loja.
O modelo dimensional organiza isso em:
Uma tabela fato (com as medidas, por exemplo valor_total, qtd_itens).
Diversas tabelas dimensão (tempo, produto, localização, cliente…).
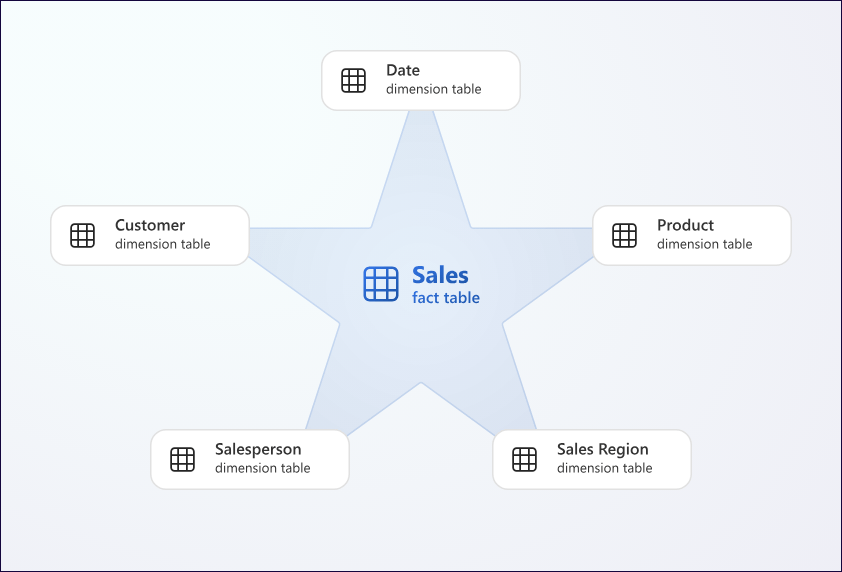
Esquema em estrela (Star Schema) e visão cúbica
É uma representação intuitiva de um evento….
Quando representamos essa estrutura em um SGBD relacional, a configuração mais comum é o esquema em estrela:
- No centro: a tabela fato (
Fato_Venda). - Em volta: as tabelas dimensão (
Dim_Tempo,Dim_Produto,Dim_Cliente,Dim_Regiaoetc.), cada uma ligada à fato por uma chave estrangeira.
Visualmente, isso forma uma “estrela”. Conceitualmente, é uma maneira de misturar:
- uma visão de negócio (fatos e dimensões)
- com uma implementação relacional (tabelas, chaves, FKs, índices).
- Um cubo 3D para
Tempo x Produto x Região.
Do ponto de vista analítico, falamos muitas vezes em cubo de dados:
– Se adicionarmos mais uma dimensão (por ex., Cliente), temos um hipercubo (mais de 3 dimensões).
– Essa visão cúbica é uma forma intuitiva de entender que cada célula contém medidas agregadas (volume de vendas, valor, margem etc.).
Tipos de medidas em tabelas fato
As colunas numéricas da tabela fato — as medidas — podem ser classificadas em:
Aditivas
Podem ser somadas em todas as dimensões.
Ex.: qtd_itens, valor_venda. Você pode somar por dia, por mês, por região, por produto.
Semi-aditivas
Podem ser somadas em algumas dimensões, mas não em todas.
Ex.: saldo_estoque: faz sentido somar estoques de diferentes produtos em uma mesma data,
mas não somar saldos ao longo do tempo (somar “saldo do dia 1” + “saldo do dia 2” não faz sentido).
Não-aditivas
Não podem ser somadas em nenhuma dimensão.
Ex.: uma taxa ou porcentagem (margem %, desconto %). Para analisá-las, geralmente precisamos de médias ponderadas ou outras formas de agregação.
Essa distinção é importante para desenhar relatórios corretos e evitar interpretações erradas.
OLTP x OLAP: por que o DW é diferente ?
Nos sistemas operacionais do dia a dia (OLTP – On-Line Transaction Processing), o foco é:
- transações curtas (inserir um pedido, atualizar um cadastro),
- consultas simples (buscar um cliente, exibir um pedido),
- poucos registros por operação, mas
- muitas operações de escrita (inserts/updates) o tempo todo.
Já em um Data Warehouse (DW) ou ambiente OLAP – On-Line Analytical Processing, a lógica se inverte:
- grande volume de dados históricos,
- atualizações menos frequentes (cargas diárias, horárias, etc.),
- consultas complexas, agregando dados em várias dimensões (tempo, produto, região…),
- foco em leitura, agrupamento e agregação.
Por isso, esquemas de DW:
- usam star schemas muitas vezes desnormalizados nas dimensões, para simplificar as consultas (por exemplo, níveis hierárquicos de produto na mesma tabela dimensão);
- exploram técnicas específicas de indexação e otimização para leitura massiva;
- suportam cubos de dados e comandos SQL específicos, como
ROLLUPeCUBE.
Um padrão muito comum de consulta OLAP é:
JOIN → FILTRA → AGRUPA → AGREGA
Por exemplo, sumarizar vendas por região e mês, usando GROUP BY e ROLLUP para obter subtotais por:
- mês dentro do ano,
- ano,
- e um total geral, em uma única query.
Muitos sistemas de BI (Power BI, Tableau, Looker, etc.) vão gerar SQL desse tipo por trás das visualizações.
Para quem quiser se aprofundar no assunto de modelagem dimensional e Data Warehouse, seguem as referências clássicas:
Ralph Kimball, Margy Ross – “The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling”
- Clássico absoluto da modelagem dimensional.
- Foca em fatos, dimensões, star schema, tipos de fatos, boas práticas de projeto.
Ralph Kimball, Joe Caserta – “The Data Warehouse ETL Toolkit”
- Focado na parte de integração e carga de dados (ETL): como extrair, transformar e carregar dados para o DW.
W. H. Inmon – “Building the Data Warehouse”
- Referência importante para o conceito de Data Warehouse corporativo em nível mais conceitual/arquitetural.
- Complementa a visão de Kimball com um enfoque mais top-down.
Aqui apresento um link para um tutorial da Microsoft Learn, com mais informações sobre o assunto. Ele é direcionado ao Microsoft Fabric, uma plataforma em nuvem para análise de dados, mas tem um bom material prático e gratuito.
Tutorial do Microsoft Fabric.
Esse é um assunto extenso, mas a ideia aqui era dar uma pincelada inicial sobre modelagem de dados. Quem sabe eu me motivo a fazer um exercício completo de ETL ? Vamos ver ….
Por hoje é isso pessoal. Até o próximo post.



Leave a comment