
Melhorando a estrutura do seu notebook
Retomando o blog Data Science Lab depois de um longo inverno congelante!
Vamos começar a falar sobre o meu aprendizado na especialização em Ciência de Dados da PUC-RIO finalizada em 2023.
Alguns professores mostraram uma forma muito melhor de criar notebooks, usando a classe de Pipeline do Sklearn. É uma solução muito boa para estruturar seu notebook, facilitando o entendimento e o reaproveitamento de código.
Nos exemplos que eu mostrei aqui no blog e publiquei no Kaggle, que em geral não usaram pipeline, percebi que o código do notebook fica meio desorganizado. Claro, esses notebooks tem o caráter didático onde focamos em um determinado aprendizado: algumas vezes queremos apenas ver como funciona a limpeza de dados, ou ver o funcionamento de um algoritmo, ou montar uma rede neural, mas sempre para fixar o aprendizado.
Falando um pouco sobre o processo de criação do projeto de Ciência de dados, podemos usar essa imagem baseada no processo KDD, ilustrada no livro Introdução a Data Science (Escovedo e Koshiyama).
Esse livro fala bastante do processo de ML focando na parte de pré-processamento dos dados, limpeza e análise. Repare que em qualquer notebook já fazemos este processo, mesmo que de forma didática, desde a definição do problema, carregamento de dados, processamento e modelagem, até a apresentação de resultados. No capítulo 11, os autores chegam a fornecer um Template consistente com esse processo, que podemos usar em nossos notebooks. Não por acaso, um dos autores do livro, foi minha professora nesta especialização da PUC!
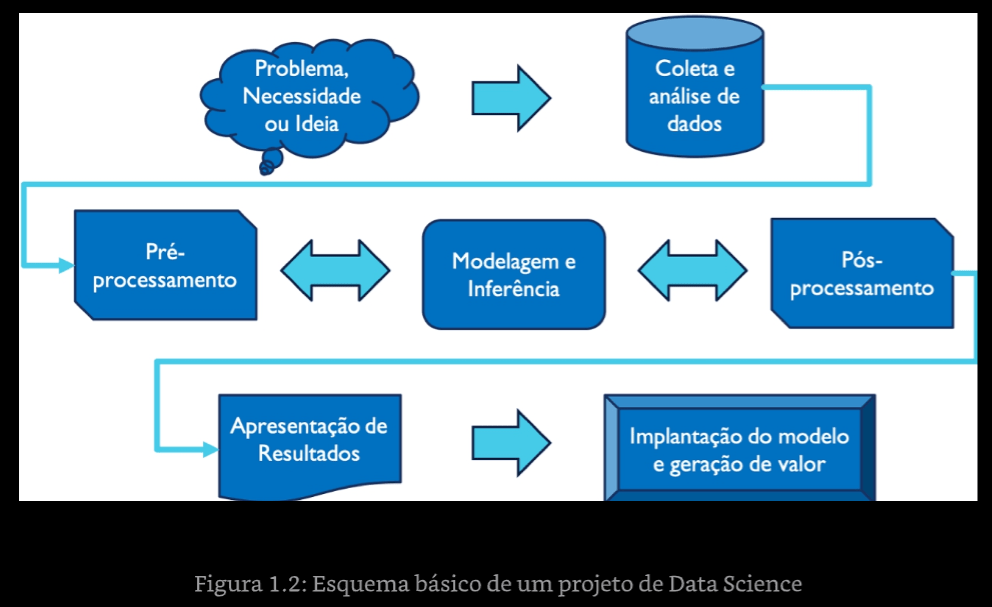
Fluxo ilustrado no livro Introdução a Data Science
Nesse contexto, podemos fazer um parênteses para refletir sobre os papéis necessários dentro do processo de criação de um modelo de ML. Como eles estão cada vez mais especializados, da análise de negócio ao deploy temos diversos profissionais que vão participar do processo. Claro, dependendo do tamanho da empresa, um mesmo profissional vai exercer mais de um desses papéis.
Sobre esse assunto, temos alguns vídeos bem explicativos no Youtube, que mostram como as empresas estão trabalhando aqui em 2025.
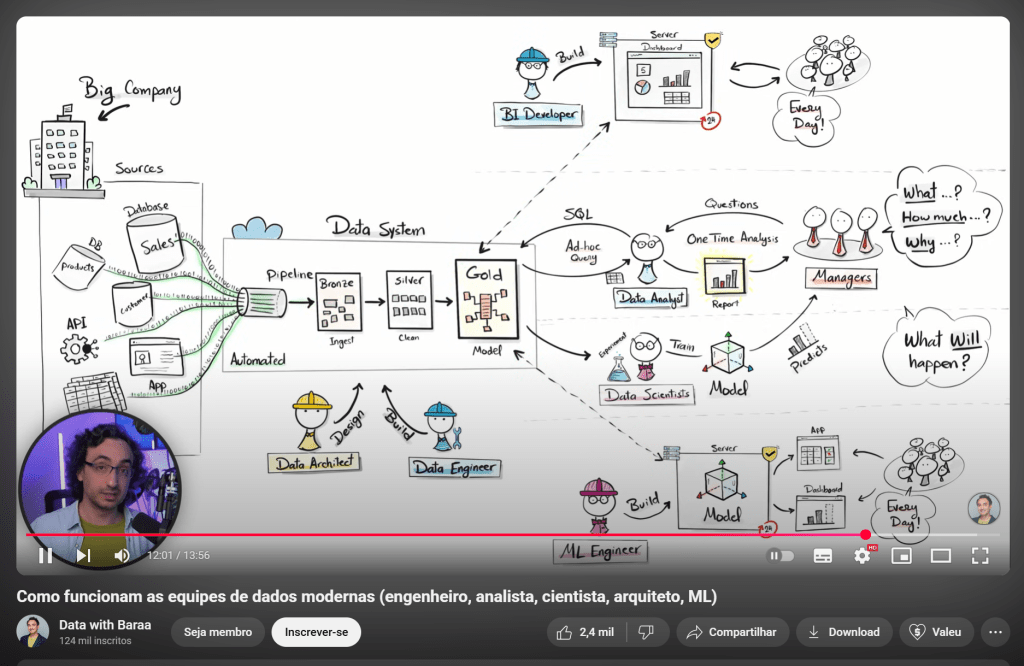
Vídeo do canal Data with Baraa
Um dos melhores que encontrei foi esse vídeo do Mr. Baraa. Ele consegue ser bem claro nos papéis que compõem a equipe de trabalho de dados. Não que seja muito diferente do desenvolvimento de software clássico, mas que detalhe as entregas de cada um deles e como eles devem trabalhar colaborativamente uns com os outros de forma a dar continuidade no “pipeline de dados”. Vale muito a pena conferir o link no final do post.
Esse assunto de Data Science Life Cycle (DSLC) é abordado de forma didática no livro Veridical Data Science. E com uma abordagem prática, temos o livro Machine Learning Production Systems, que me parece uma boa leitura para o meus próximos finais de semana!
Voltando ao assunto inicial, organizar o seu notebook de uma forma mais estruturada é muito importante para entender o processo completo e como ele se encaixa no ciclo de vida. Por exemplo, olhando para o processo, entendemos que antes do dataset chegar ao notebook, o processo de ETL já foi executado, e o nosso modelo seguirá como artefato para as próximas fases (MLOps).
Resumindo em uma Visão end-to-end moderna:
Business → Data → Model → Deployment → Monitoring → Feedback (iterativo).
O nosso notebook está alí no meio do processo, agora de forma bem organizada. Veja o exemplo disponível no Kaggle, com link no final do post: o pipeline usa funções que podem ser reaproveitadas para fazer as transformações dos dados. Usa grid search com Cross Validation para testar vários modelos e com um conjunto de parâmetros passado para eles. Por fim, mostramos como o pipeline pode ser salvo e usado por completo em produção, com todas as transformações de dados.
Vantagens do uso de pipeline:
- Código mais limpo e modular, facilitando o entendimento do fluxo de dados e transformações.
- Evita Data Leakage, visto que o
fitacontece apenas nos dados de treino e otransformé reaplicado corretamente nos dados de teste, evitando vazamento de informação. - Facilita Validação Cruzada: Você pode usar
cross_val_score,GridSearchCV, etc., diretamente com o pipeline. - Reprodutibilidade e Automação: ao salvar o pipeline (
joblib,pickle), você salva todo o processo, não só o modelo.
Ter em mente o contexto em que o cientista de dados trabalha é importante para ter uma visão do todo. Aqui nem falei do quanto uma empresa tem que se preparar para ser considerada Data Driven, e ter uma área com esses profissionais trabalhando para ela, mas isso é assunto para outro post…
Por hoje é isso. Até o próximo post.
Links:
Uso de pipeline no notebook – https://www.kaggle.com/code/cesarayres/usando-pipeline-e-gridsearch-com-titanic-dataset
Como funcionam as equipes – https://www.youtube.com/watch?v=tyJ476aNCYU&list=WL&index=24
Livro de Introdução a Data Science – https://www.amazon.com.br/Introdu%C3%A7%C3%A3o-Data-Science-Algoritmos-Learning-ebook/dp/B085CK5Z9S



Leave a comment