
Trabalhando com um dataset de 82 colunas.
Continuando a revisão do curso inicial de Machine Learning da PUC-RIO com material da Intel conforme comentamos neste post.
Depois de alguns feriados, onde eu não consegui postar por algumas semanas, hoje vamos comentar sobre a análise do dataset Mice Protein Expression (MPE). Esse é um problema de classificação multiclass onde a coluna class, nosso target, tem 8 categorias. Veja a descrição completa deste conjunto de dados no meu notebook do Kaggle (link no final do post).
Aqui vale destacar que, este exercício foi feito durante o curso, apenas para fixação do fluxo de trabalho de machine learning, sem entrar em questões mais técnicas. No entanto, eu acabei refazendo esse exercício e aprofundando um pouco (ou demais) na análise de aspectos mais complexos.
No post anterior apresentamos como usar PCA para reduzir dimensionalidade no dataset IRIS, que tinha apenas 4 atributos. No caso do dataset MPE, temos uma quantidade muito maior de atributos, o que significa que aplicar uma técnica de seleção de atributos ou de redução de dimensionalidade faz muito mais sentido. Pelo menos no aspecto de visualização das classes, ele foi bem útil.
O conjunto de dados também apresenta valores ausentes e outliers. No caso deste último, fica a pergunta: “o que é um valor de proteína considerado outlier”. No nosso notebook do Kaggle, montamos um dataset removendo outliers usando critérios estatísticos, no caso o intervalo interquartil (IQR), substituindo os valores abaixo do limite inferior, ou acima do limite superior, pelo valor limite.
E aqui foi onde eu me aprofundei mais neste estudo: no conjunto de dados MPE temos que ficar atentos para o fato de que os atributos de entrada são as proteínas presentes nas 77 colunas como sufixo “_N”. As demais são colunas de saída.
Se você considerar as colunas Genotype, Treatment type e Behavior como atributos de entrada, você vai cometer um erro grave na sua análise, visto que a informação presente nestas colunas é a mesma informação que consta na coluna class,
apenas em outro formato. Veja um exemplo:
MouseID
Genotype
Treatment
Behavior
Class
309_3
Control
Memantine
C/S
c-CS-m
Note que o modelo teria acesso a informações que definem diretamente o target, o que não é realista em um cenário de previsão!! Por consequência, seu modelo vai performar bem para dados de treino e teste, mas em produção não. Infelizmente, algumas pessoas no Kaggle cometem esse erro.
Esse é um tipo de problema em machine learning chamado Data Leakage (vazamento de dados). Além dessa forma que apresentamos, existem outras formas de ocorrer vazamento de dados:
Vazamento Temporal: Em séries temporais, se dados futuros forem incluídos no treinamento, o modelo pode prever eventos com base em informações que só estarão disponíveis posteriormente.
Processamento Inadequado de Dados: Se o pré-processamento (como normalização ou imputação de valores faltantes) for feito antes da divisão entre treino e teste, informações do conjunto de teste podem inadvertidamente “vazar” para o modelo.
Vazamento de Grupo: é um tipo sutil e complexo de data leakage que ocorre quando os dados possuem uma estrutura de agrupamento – por exemplo, múltiplas medições do mesmo sujeito ou de sujeitos pertencentes ao mesmo cluster – e essa estrutura não é respeitada na divisão entre treino e teste.
Dito isto, em uma análise mais criteriosa, devemos separar os grupos de Mouses exclusivamente em treino ou teste.
Quando temos múltiplas medições (replicatas) de um mesmo indivíduo, como é o caso dos 15 amostras de cada mouse no dataset, é absolutamente crítico garantir que nenhuma amostra de um mesmo MouseID apareça simultaneamente em treino e em teste. Se isso acontecer, o modelo pode “decorar” características idiossincráticas daquele mouse e inflar artificialmente sua performance — que é o definimos no vazamento de grupo.
Fizemos isso de forma manual, para fins didáticos, invés de usar GroupKFold, no nosso notebook do Kaggle. No final, vimos que se não fazemos essa separação dos dados de treino e teste por amostras do campo MouseID, temos uma acurácia de 99% nas nossas previsões de dados de teste. Ainda testamos essa tese usando clusterização com KMeans. Veja que em um Mice aleatório, muitas de suas amostras ficam aglutinadas no mesmo Cluster, indicando que realmente poderia ocorrer Vazamento de Dados.
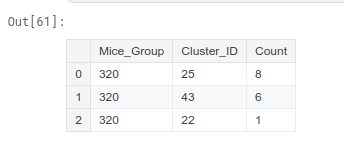
Outra questão … é que você não pode fazer preenchimento de dados ausentes usando a “média por classe”. Usar a variável alvo na modelagem dos dados é outro tipo de vazamento de dados!
Mas, como vocês podem notar, esse é um assunto muito extenso. Veja por exemplo as referências usadas no Wikipedia na definição deste esse assunto. Ou faça uma busca no Google sobre Data Leakage! Realmente devemos ficar muito atentos ao Vazamento de Dados quando trabalhamos com Machine Learning, inclusive, até mesmo quando o dataset parece ser “simples”.
Por fim, assista aos dois vídeos nos links abaixo!
O primeiro vídeo mostra uma apresentação bem estruturada de um trabalho com o nosso dataset MPE. Já o segundo é uma excelente aula sobre Data Leakage!
Por hoje é isso. Até o próximo post!
Links do post:
O meu notebook no Kaggle –https://www.kaggle.com/code/cesarayres/mice-protein-classification
Trabalho sobre o dataset MPE – https://www.youtube.com/watch?v=jitlavJEh-o
Vídeo sobre Data Leakage – https://www.youtube.com/watch?v=dWhdWxgt5SU




Leave a comment