
Continuando uma rápida revisão dos exercícios propostos no curso de extensão, introdutório à inteligência artificial da Puc-Rio com material da Intel, como foi comentando inicialmente nesse post.
Hoje vamos explorar um dataset simples para mostrar um problema de classificação multiclasse que, diferente da classificação binária, envolve mais de duas categorias como alvo da previsão do modelo.
No caso, o dataset IRIS tem três espécies da flor de iris. Cada uma delas tem suas próprias características de comprimento e largura para pétala e sépala. São apenas esses quatro atributos que compõem o nosso conjunto de dados e o nosso atributo rótulo (ou alvo).
Não confundir um problema multiclasse (ou multiclass) com um problema multirotulo (ou multilabel). No livro de Aurélio Géron, “Mãos à Obra: Aprendizado de Máquina com Scikit-Learn, Keras & TensorFlow“, ele explica essas diferenças com exemplos. Aqui eu posso dizer que um exemplo de classificação multirotulo seria a classificação de um filme por gênero, tal como drama, ação ou suspense. Um filme poderia ter mais de um gênero ao mesmo tempo, diferente da nossa flor de iris que pertence a uma única espécie.
- Muilticlass: significa que temos um único rótulo com classificações diferentes.
- Multilabel: uma mesma instância pertence a mais de um rótulo ao mesmo tempo.
No notebook do Kaggle, com link no final do post, fazemos o load do dataset Iris disponível na biblioteca Sklearn. Além deste, outros Toy Datasets estão disponíveis para aprendizado, conforme o link no final deste post. Essa facilidade é muito útil para quem está começando e quer praticar, sem ter que manipular o arquivo de dados.
O Sklearn também consegue criar dados sintéticos para seus experimentos, e disponibiliza outros datasets maiores (Real World) que podem ser usados em problemas de machine learning e até de deep learning, como reconhecimento facial.
O dataset IRIS é relativamente simples, e tem algumas características interessantes:
- Balanceamento Perfeito – Cada uma das três classes tem exatamente 50 amostras, o que facilita a análise e modelagem sem precisar lidar com desbalanceamento.
- Separabilidade das Classes – A classe Setosa é facilmente separável das outras duas com base no comprimento e largura das pétalas. Já Versicolor e Virginica são mais sobrepostas, com algum grau de dificuldade na classificação.
- Baixa Dimensionalidade – Ele tem apenas quatro atributos, tornando-o pequeno e fácil de visualizar.
- Ausência de Valores Faltantes – Não há valores nulos ou ausentes, o que é incomum em datasets reais. Isso evita a necessidade de pré-processamento adicional.
No nosso exercício, fizemos a análise exploratória dos conjunto de dados, mostramos como ele fica visualmente em uma Análise de Componentes Principais (PCA).
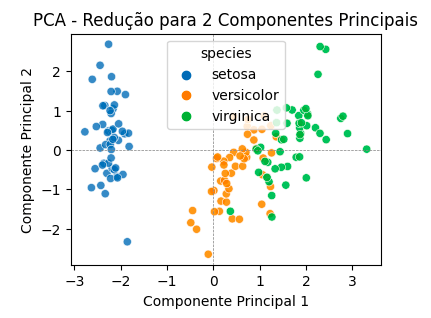
A Análise Componentes Principais é uma técnica estatística de redução de dimensionalidade que se baseia em álgebra linear
e na projeção ortogonal dos dados em novos eixos, os chamados componentes principais. O objetivo da PCA é reduzir a quantidade de atributos enquanto preserva o máximo possível da informação original. Por isso, é amplamente utilizado em cenários onde desejamos diminuir a complexidade dos dados sem perder sua essência, como em visualizações, compressão de dados ou pré-processamento para modelos de machine learning.
E falamos sobre o conceito de modelo multiclass, mostrando como usar um modelo binário adaptado para um problema multiclass. Na verdade o SKlearn já faz esse trabalho internamente nos algoritmos que ele disponibiliza, mas é bom entender como isso funciona.
Por hoje era isso. Até o próximo post!
Links do post:
Toy Datasets – https://scikit-learn.org/stable/datasets/toy_dataset.html
Link do Notebook – https://www.kaggle.com/code/cesarayres/pca-e-classifica-o-muiticlass-com-iris




Leave a comment